Developers
API References
Data Subject Request API
Data Subject Request API Version 1 and 2
Data Subject Request API Version 3
Platform API
Key Management
Platform API Overview
Accounts
Apps
Audiences
Calculated Attributes
Data Points
Feeds
Field Transformations
Services
Users
Workspaces
Warehouse Sync API
Warehouse Sync API Overview
Warehouse Sync API Tutorial
Warehouse Sync API Reference
Data Mapping
Warehouse Sync SQL Reference
Warehouse Sync Troubleshooting Guide
ComposeID
Warehouse Sync API v2 Migration
Audit Logs API
Bulk Profile Deletion API Reference
Calculated Attributes Seeding API
Data Planning API
Custom Access Roles API
Group Identity API Reference
Pixel Service
Profile API
Events API
mParticle JSON Schema Reference
IDSync
Client SDKs
AMP
AMP SDK
Android
Initialization
Configuration
Network Security Configuration
Event Tracking
User Attributes
IDSync
Screen Events
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Push Notifications
WebView Integration
Logger
Preventing Blocked HTTP Traffic with CNAME
Workspace Switching
Linting Data Plans
Troubleshooting the Android SDK
API Reference
Upgrade to Version 5
Cordova
Cordova Plugin
Identity
Direct Url Routing
Direct URL Routing FAQ
Web
Android
iOS
iOS
Workspace Switching
Initialization
Configuration
Event Tracking
User Attributes
IDSync
Screen Tracking
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Push Notifications
Webview Integration
Upload Frequency
App Extensions
Preventing Blocked HTTP Traffic with CNAME
Linting Data Plans
Troubleshooting iOS SDK
Social Networks
iOS 14 Guide
iOS 15 FAQ
iOS 16 FAQ
iOS 17 FAQ
iOS 18 FAQ
API Reference
Upgrade to Version 7
React Native
Getting Started
Identity
Unity
Upload Frequency
Getting Started
Opt Out
Initialize the SDK
Event Tracking
Commerce Tracking
Error Tracking
Screen Tracking
Identity
Location Tracking
Session Management
Web
Initialization
Configuration
Content Security Policy
Event Tracking
User Attributes
IDSync
Page View Tracking
Commerce Events
Location Tracking
Media
Kits
Application State and Session Management
Data Privacy Controls
Error Tracking
Opt Out
Custom Logger
Persistence
Native Web Views
Self-Hosting
Multiple Instances
Web SDK via Google Tag Manager
Preventing Blocked HTTP Traffic with CNAME
Facebook Instant Articles
Troubleshooting the Web SDK
Browser Compatibility
Linting Data Plans
API Reference
Upgrade to Version 2 of the SDK
Xamarin
Getting Started
Identity
Alexa
Quickstart
Android
Overview
Step 1. Create an input
Step 2. Verify your input
Step 3. Set up your output
Step 4. Create a connection
Step 5. Verify your connection
Step 6. Track events
Step 7. Track user data
Step 8. Create a data plan
Step 9. Test your local app
iOS Quick Start
Overview
Step 1. Create an input
Step 2. Verify your input
Step 3. Set up your output
Step 4. Create a connection
Step 5. Verify your connection
Step 6. Track events
Step 7. Track user data
Step 8. Create a data plan
Python Quick Start
Step 1. Create an input
Step 2. Create an output
Step 3. Verify output
Server SDKs
Node SDK
Go SDK
Python SDK
Ruby SDK
Java SDK
Guides
Partners
Introduction
Outbound Integrations
Outbound Integrations
Firehose Java SDK
Inbound Integrations
Compose ID
Data Hosting Locations
Glossary
Migrate from Segment to mParticle
Migrate from Segment to mParticle
Migrate from Segment to Client-side mParticle
Migrate from Segment to Server-side mParticle
Segment-to-mParticle Migration Reference
Rules Developer Guide
API Credential Management
The Developer's Guided Journey to mParticle
Guides
Composable Audiences
Composable Audiences Overview
User Guide
User Guide Overview
Warehouse Setup
Warehouse Setup Overview
Audience Setup
Frequently Asked Questions
Customer 360
Overview
User Profiles
Overview
User Profiles
Group Identity
Overview
Create and Manage Group Definitions
Calculated Attributes
Calculated Attributes Overview
Using Calculated Attributes
Create with AI Assistance
Calculated Attributes Reference
Predictions
Predictions Overview
What's Changed in the New Predictions UI
View and Manage Predictions
Predict Future Behavior
Future Behavior Predictions Overview
Create Future Behavior Prediction
Manage Future Behavior Predictions
Create an Audience with Future Behavior Predictions
Identity
Identity Dashboard
Identity Logs
Getting Started
Create an Input
Start capturing data
Connect an Event Output
Create an Audience
Connect an Audience Output
Transform and Enhance Your Data
Platform Guide
Billing
Usage and Billing Report
The New mParticle Experience
The new mParticle Experience
The Overview Map
Observability
Observability Overview
Observability User Guide
Observability Troubleshooting Examples
Observability Span Glossary
Platform Settings
Key Management
Audit Logs
Platform Configuration
Event Forwarding
Event Match Quality Dashboard
Notifications
System Alerts
Trends
Introduction
Data Retention
Data Catalog
Connections
Activity
Data Plans
Live Stream
Filters
Rules
Blocked Data Backfill Guide
Tiered Events
mParticle Users and Roles
Analytics Free Trial
Troubleshooting mParticle
Usage metering for value-based pricing (VBP)
IDSync
IDSync Overview
Use Cases for IDSync
Components of IDSync
Store and Organize User Data
Identify Users
Default IDSync Configuration
Profile Conversion Strategy
Profile Link Strategy
Profile Isolation Strategy
Best Match Strategy
Aliasing
Segmentation
Audiences
Audiences Overview
Create an Audience
Connect an Audience
Manage Audiences
Audience Sharing
Audience Expansion (Early Access)
Match Boost
FAQ
Inclusive & Exclusive Audiences (Early Access)
Inclusive & Exclusive Audiences Overview
Using Logic Blocks in Audiences
Combining Inclusive and Exclusive Audiences
Inclusive & Exclusive Audiences FAQ
Classic Audiences
Standard Audiences (Legacy)
Predictive Audiences
Predictive Audiences Overview
Using Predictive Audiences
New vs. Classic Experience Comparison
Analytics
Introduction
Core Analytics (Beta)
Setup
Sync and Activate Analytics User Segments in mParticle
User Segment Activation
Welcome Page Announcements
Settings
Project Settings
Roles and Teammates
Organization Settings
Global Project Filters
Portfolio Analytics
Analytics Data Manager
Analytics Data Manager Overview
Events
Event Properties
User Properties
Revenue Mapping
Export Data
UTM Guide
Analyses
Analyses Introduction
Segmentation: Basics
Getting Started
Visualization Options
For Clauses
Date Range and Time Settings
Calculator
Numerical Settings
Segmentation: Advanced
Assisted Analysis
Properties Explorer
Frequency in Segmentation
Trends in Segmentation
Did [not] Perform Clauses
Cumulative vs. Non-Cumulative Analysis in Segmentation
Total Count of vs. Users Who Performed
Save Your Segmentation Analysis
Export Results in Segmentation
Explore Users from Segmentation
Funnels: Basics
Getting Started with Funnels
Group By Settings
Conversion Window
Tracking Properties
Date Range and Time Settings
Visualization Options
Interpreting a Funnel Analysis
Funnels: Advanced
Group By
Filters
Conversion over Time
Conversion Order
Trends
Funnel Direction
Multi-path Funnels
Analyze as Cohort from Funnel
Save a Funnel Analysis
Export Results from a Funnel
Explore Users from a Funnel
Saved Analyses
Manage Analyses in Dashboards
Query Builder
Data Dictionary
Query Builder Overview
Modify Filters With And/Or Clauses
Query-time Sampling
Query Notes
Filter Where Clauses
Event vs. User Properties
Group By Clauses
Annotations
Cross-tool Compatibility
Apply All for Filter Where Clauses
Date Range and Time Settings Overview
User Attributes at Event Time
Understanding the Screen View Event
User Aliasing
Dashboards
Dashboards––Getting Started
Manage Dashboards
Dashboard Filters
Organize Dashboards
Scheduled Reports
Favorites
Time and Interval Settings in Dashboards
Query Notes in Dashboards
Analytics Resources
The Demo Environment
Keyboard Shortcuts
User Segments
Data Privacy Controls
Data Subject Requests
Default Service Limits
Feeds
Cross-Account Audience Sharing
Import Data with CSV Files
Import Data with CSV Files
CSV File Reference
Glossary
Video Index
Analytics (Deprecated)
Identity Providers
Single Sign-On (SSO)
Setup Examples
Introduction
Developer Docs
Introduction
Integrations
Introduction
Rudderstack
Google Tag Manager
Segment
Data Warehouses and Data Lakes
Advanced Data Warehouse Settings
AWS Kinesis (Snowplow)
AWS Redshift (Define Your Own Schema)
AWS S3 Integration (Define Your Own Schema)
AWS S3 (Snowplow Schema)
BigQuery (Snowplow Schema)
BigQuery Firebase Schema
BigQuery (Define Your Own Schema)
GCP BigQuery Export
Snowflake (Snowplow Schema)
Snowplow Schema Overview
Snowflake (Define Your Own Schema)
Developer Basics
Aliasing
Integrations
24i
Event
Aarki
Audience
ABTasty
Audience
Actable
Feed
AdChemix
Event
AdMedia
Audience
Adobe Marketing Cloud
Cookie Sync
Platform SDK Events
Server-to-Server Events
Adobe Audience Manager
Audience
Adobe Experience Platform
Event
Adobe Campaign Manager
Audience
Adobe Target
Audience
AdPredictive
Feed
AgilOne
Event
Algolia
Event
Amazon Advertising
Audience
Amazon Kinesis
Event
Amazon S3
Event
Amazon Redshift
Data Warehouse
Amazon SNS
Event
Amazon SQS
Event
Amobee
Audience
Anodot
Event
Antavo
Feed
Apptentive
Event
Awin
Event
Apptimize
Event
Apteligent
Event
Microsoft Azure Blob Storage
Event
Bidease
Audience
Bing Ads
Event
Bluecore
Event
Bluedot
Feed
Branch S2S Event
Event
Bugsnag
Event
Cadent
Audience
Census
Feed
comScore
Event
Conversant
Event
Crossing Minds
Event
Custom Feed
Custom Feed
Databricks
Data Warehouse
Didomi
Event
Datadog
Event
Eagle Eye
Audience
Edge226
Audience
Emarsys
Audience
Epsilon
Event
Everflow
Audience
Facebook Offline Conversions
Event
Google Analytics for Firebase
Event
Flurry
Event
Flybits
Event
ForeSee
Event
FreeWheel Data Suite
Audience
Friendbuy
Event
Google Ad Manager
Audience
Google Analytics
Event
Google BigQuery
Audience
Data Warehouse
Google Analytics 4
Event
Google Enhanced Conversions
Event
Google Marketing Platform
Audience
Cookie Sync
Event
Google Marketing Platform Offline Conversions
Event
Google Pub/Sub
Event
Google Tag Manager
Event
Heap
Event
Herow
Feed
Hightouch
Feed
Hyperlocology
Event
Ibotta
Event
ID5
Kit
Impact
Event
Inspectlet
Event
Intercom
Event
InMarket
Audience
Kafka
Event
ironSource
Audience
Kissmetrics
Event
Kubit
Event
LaunchDarkly
Feed
LifeStreet
Audience
LiveLike
Event
Liveramp
Audience
Localytics
Event
MadHive
Audience
mAdme Technologies
Event
Marigold
Audience
MediaMath
Audience
Microsoft Ads
Microsoft Ads Audience Integration
Mediasmart
Audience
Microsoft Azure Event Hubs
Event
Mintegral
Audience
Monetate
Event
Movable Ink
Event
Movable Ink - V2
Event
Multiplied
Event
Nami ML
Feed
Nanigans
Event
NCR Aloha
Event
Neura
Event
OneTrust
Event
Oracle BlueKai
Event
Paytronix
Feed
Persona.ly
Audience
Personify XP
Event
Plarin
Event
Primer
Event
Qualtrics
Event
Quantcast
Event
Rakuten
Event
Reveal Mobile
Event
RevenueCat
Feed
Salesforce Mobile Push
Event
Scalarr
Event
Shopify
Feed
Custom Pixel
SimpleReach
Event
Singular-DEPRECATED
Event
Skyhook
Event
Smadex
Audience
Slack
Event
SmarterHQ
Event
Snapchat Conversions
Event
Snowflake
Audience
Data Warehouse
Snowplow
Event
Splunk MINT
Event
StartApp
Audience
Tapad
Audience
Talon.One
Audience
Event
Loyalty Feed
Feed
Tapjoy
Audience
Taplytics
Event
Taptica
Audience
Teak
Audience
Ticketure
Feed
The Trade Desk
Cookie Sync
Audience
Event
Triton Digital
Audience
TUNE
Event
Valid
Event
Vkontakte
Audience
Webhook
Event
Vungle
Audience
White Label Loyalty
Event
Webtrends
Event
Wootric
Event
Xandr
Audience
Cookie Sync
Yotpo
Feed
Yahoo (formerly Verizon Media)
Audience
Cookie Sync
YouAppi
Audience
Regal
Event
Data Warehouse
The mParticle integration with Databricks allows you to forward your data from mParticle to Databricks. Databricks is a Delta Lake platform built on Apache Spark and facilitates both distributed data storage and computation. When connected to Databricks, arbitrary work, and SQL queries can be scheduled to run against a configured Compute Cluster or SQL Warehouse, whose capacity can be tailored according to your needs.
Prerequisites
Before setting up the Databricks integration within mParticle, you must configure the following within your Databricks account:
-
A dedicated Service Principal to allow mParticle to upload data to your Databricks catalog.
- When creating a Service Principal, you will create a Client ID / Client Secret pair. These credentials will be used by mParticle to generate OAuth access tokens to upload data to your catalog on your behalf.
- After creating your new service principal, make sure to grant it access to both the SQL Warehouse and either the Catalog or Schema you create for this integration. If not, the access token that mParticle generates on behalf of the Service Principal won’t allow access to your Databricks resources.
- A SQL Warehouse to run future queries.
- A Catalog and Schema within your Databricks workspace.
1. Create a new Service Principal
A service principal in Databricks is an API-only identity used to grant automated tools and applications, like mParticle, secure access to your data catalogs. mParticle will use the service principal you create to authenticate itself when forwarding your data to Databricks.
To create a new Service Principal:
- Navigate to Settings, and select Identity and access under Workspace admin.
- Click Manage under Service principals.
- Click Add service principal.
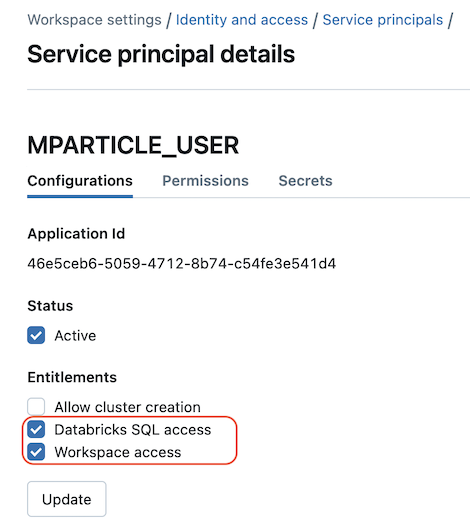
- Make sure to enable Databricks SQL access and Workspace access under Entitlements. You can enable these for an existing service principal by navigating to the Configurations tab when viewing the service principal and enabling both settings before clicking Update.
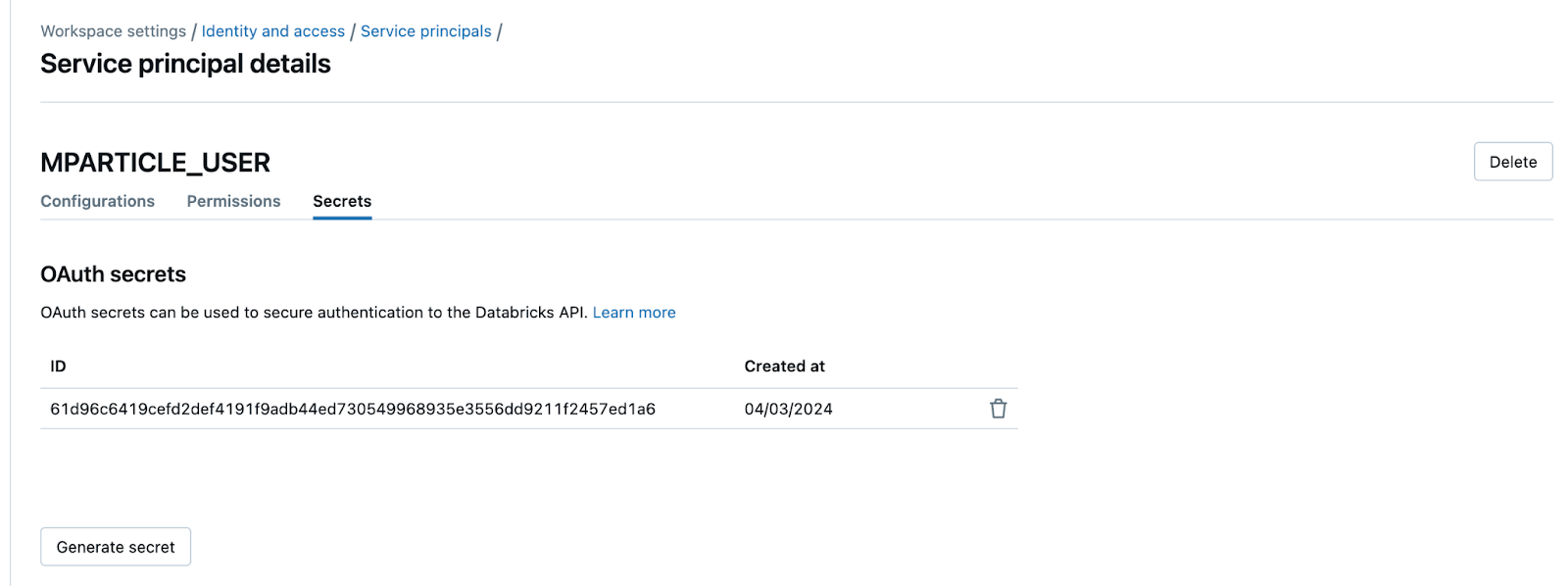
- After creating your new service principal, go to the Secrets tab on the Service principal details page, and click Generate secret.
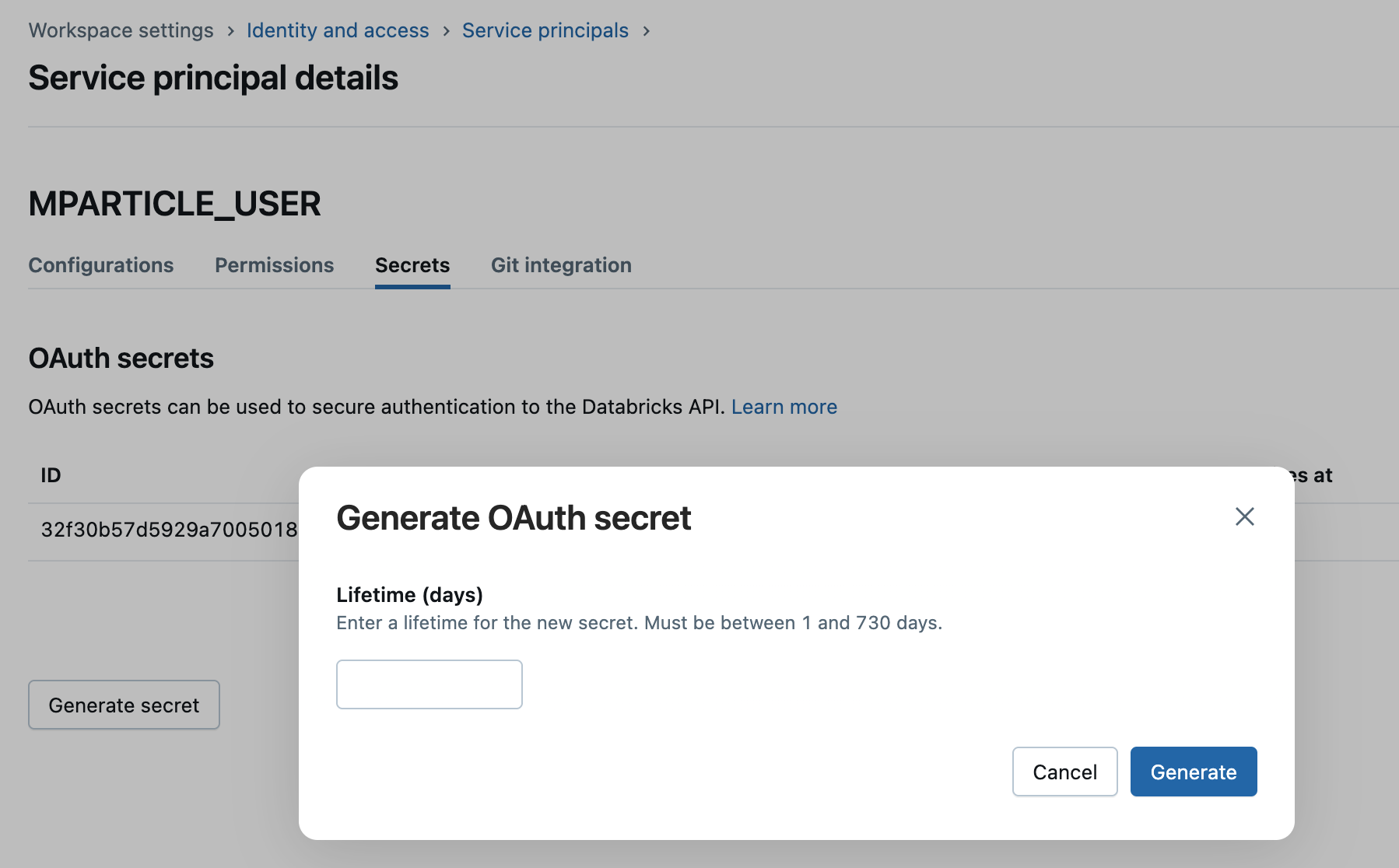
- Under Lifetime (days), enter how long you want your OAuth secret to be valid, and click Generate. Save the Client ID and Client Secret that are displayed, as you will need to enter them when configuring your connection to Databricks in mParticle.
To learn more about Service Principals, visit the Databricks documentation: Manage service principals.
2. Create a SQL Warehouse
A SQL Warehouse within Databricks is a computational resource that allows you to run SQL queries on your data. You will need to create a SQL Warehouse that mParticle can use when forwarding your data.
To create a new SQL warehouse:
- Log into your Databricks account.
- Under SQL in the left hand nav, select SQL Warehouses.
- Click Create SQL warehouse.
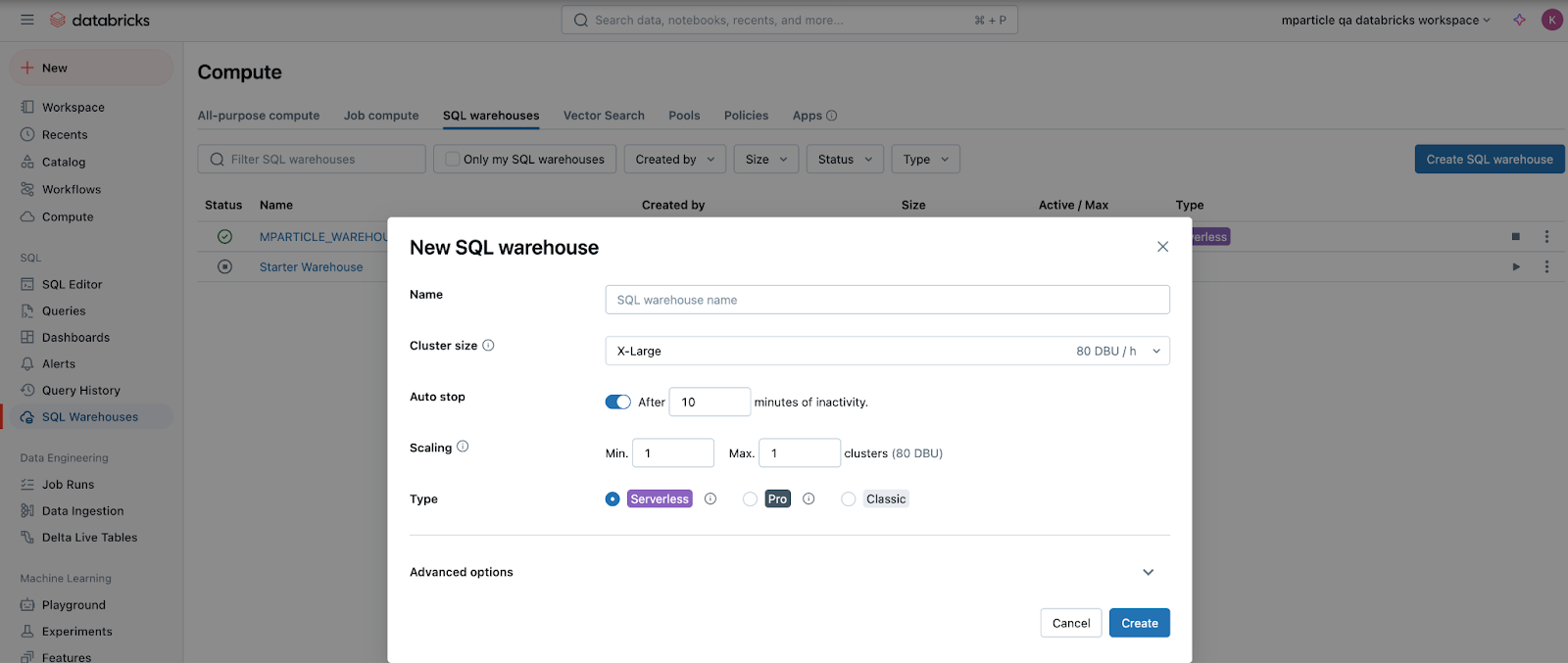
- Enter a meaningful name for your new warehouse, and select a cluster size appropriate for your organization’s needs.
- Under Auto stop, enter a time duration appropriate for your organization. Note that “cold” cluster start-up times can reach several minutes, which may impact how efficiently mParticle is able to forward data to Databricks.
- Under Type, select Serverless.
- Click Create.
- Update Permissions to grant access for this SQL Warehouse to the new Service Principal you created in 1 Create a new Service Principal.
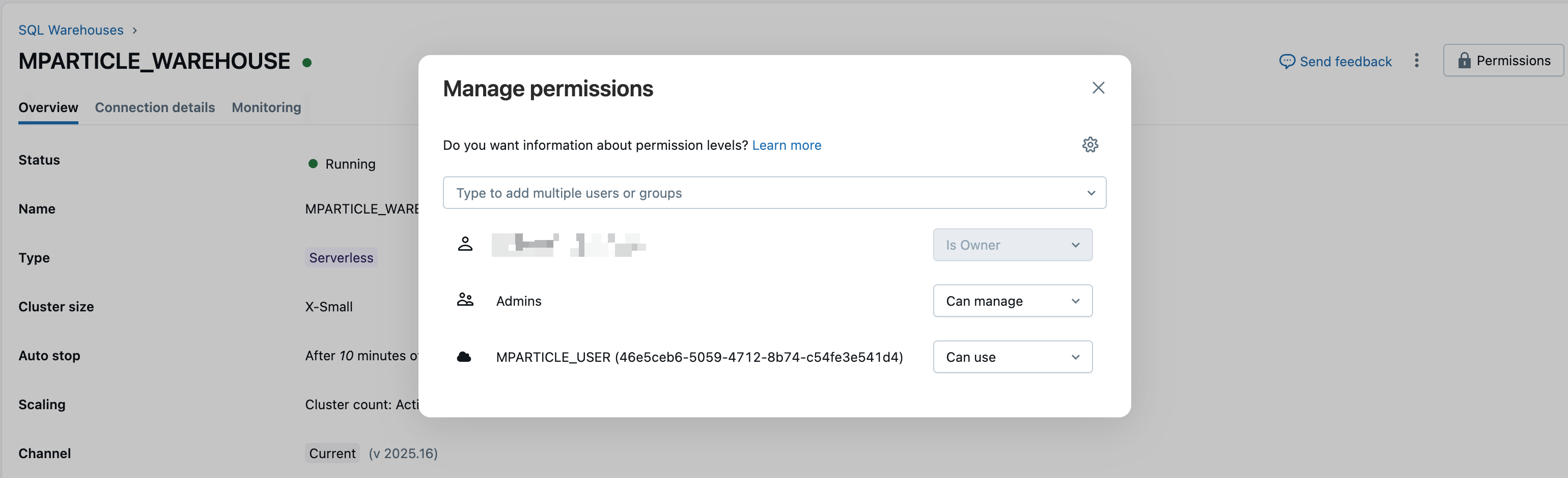
To learn more about SQL warehouses and their configuration settings, visit the Databricks documentation: Create a SQL warehouse.
3. Create a new Catalog
All data in Databricks is organized within Catalogs. Catalogs contain Schemas that define the structure of your data, and tables that contain the data itself.
To create a new catalog:
- Navigate to Catalog in the left hand nav of your Databricks workspace.
- Click Create Catalog.
- Under Type, select Standard, or whichever type best suits your organization’s use case. The mParticle Databricks integration supports all catalog types.
- Click Create.
- After creating and opening your catalog, go to the Permissions tab.
-
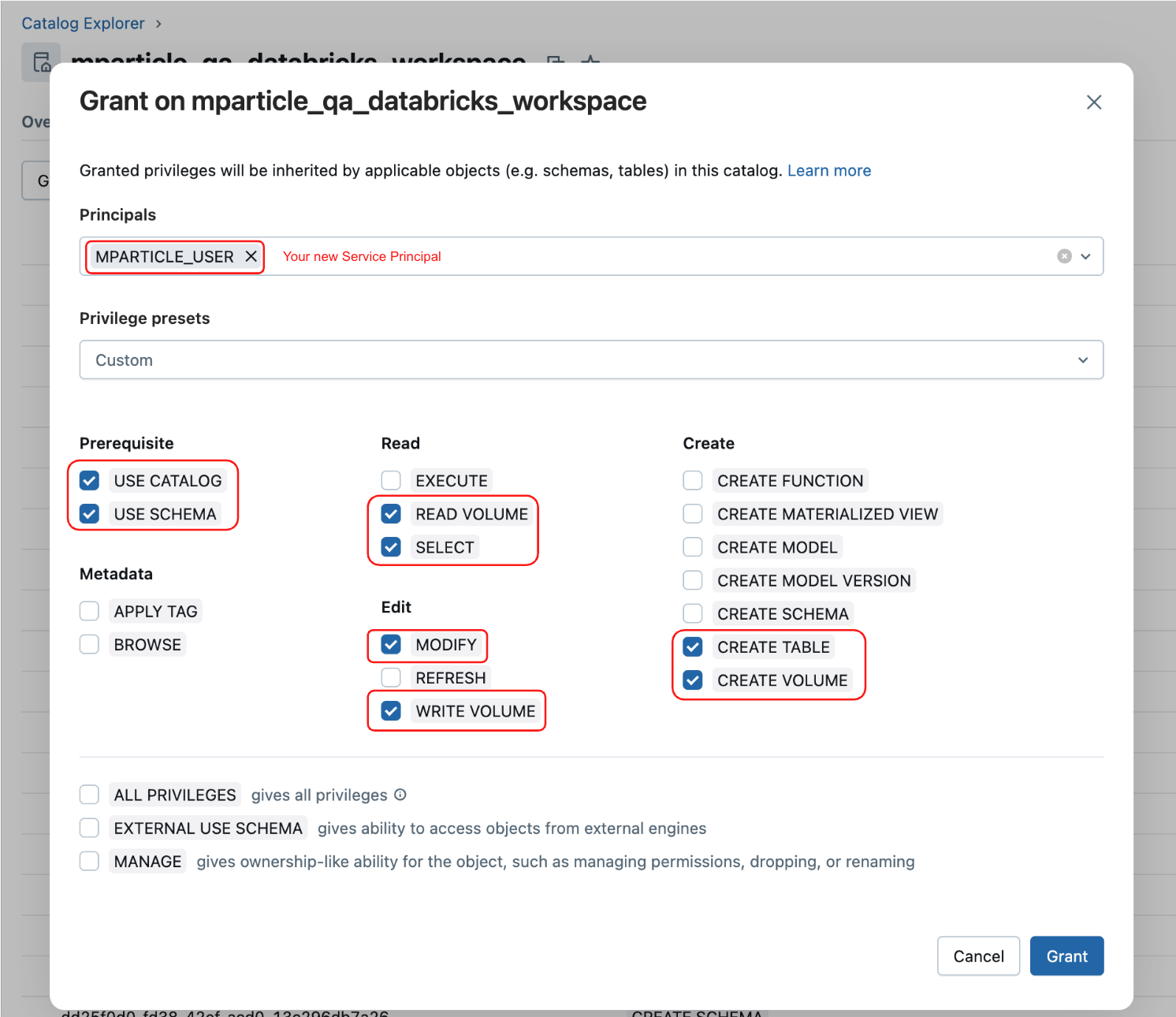
Click Grant, enter the service principal you created in 1 Create a new Service Principal under Principals, and enable the following privileges to ensure mParticle can generate the necessary tables in your catalog:
- USE CATALOG
- USE SCHEMA
- SELECT
- MODIFY
- READ VOLUME
- WRITE VOLUME
- CREATE TABLE
- CREATE VOLUME
You can learn more about catalogs in the Databricks documentation: What are catalogs in Databricks?
4. Create a new Schema
Within the Databricks data hierarchy, a schema is a subcomponent of a catalog that defines in more granularity how your data is organized and structured.
To create a new schema:
- Navigate to Catalog in the left hand nav of your Databricks workspace.
- Select the catalog you created in the previous step, and click Create schema.
- Enter a meaningful name and description before clicking Create.
- Since you already granted read/write privileges to your service principal for the catalog containing this schema, you don’t need to grant it privileges here. However, depending on how your organization has structured your Databricks workspace, you may choose instead to set these privileges at the schema scope instead of the catalog scope.
It is also possible to create a new schema using the Databricks SQL Editor.
Configure your Databricks integration in mParticle
1. Create an outbound configuration for Databricks
To create an outbound configuration for Databricks within mParticle:
- Log into your mParticle account.
- From the Overview Map in the new UI, click Add under Outputs. If you’re using the Classic UI, navigate to Setup > Outputs in the left hand nav bar.
- Go to the Data Warehouse tab and use the Add Data Warehouse dropdown menu to add a new Databricks configuration.
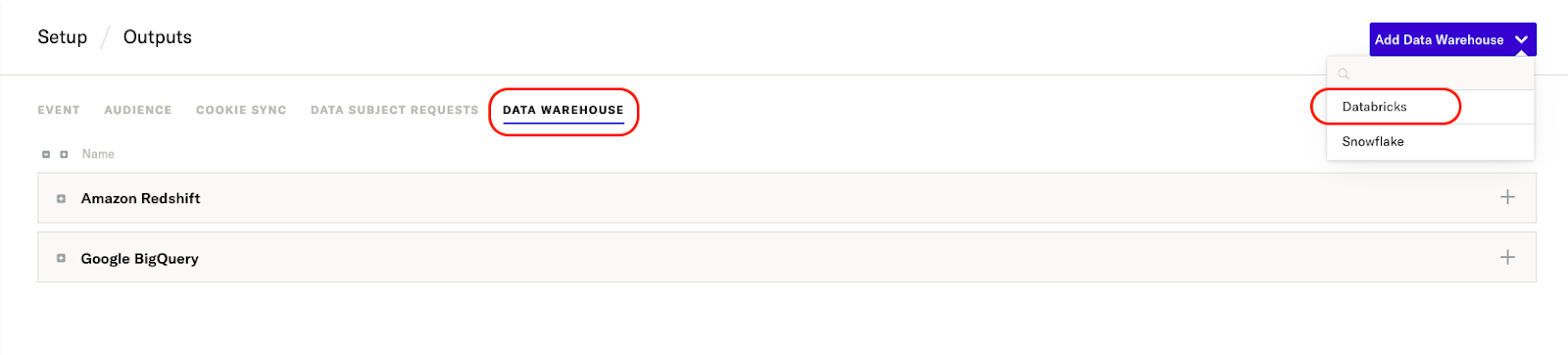
- Hover over Databricks and click Configure.
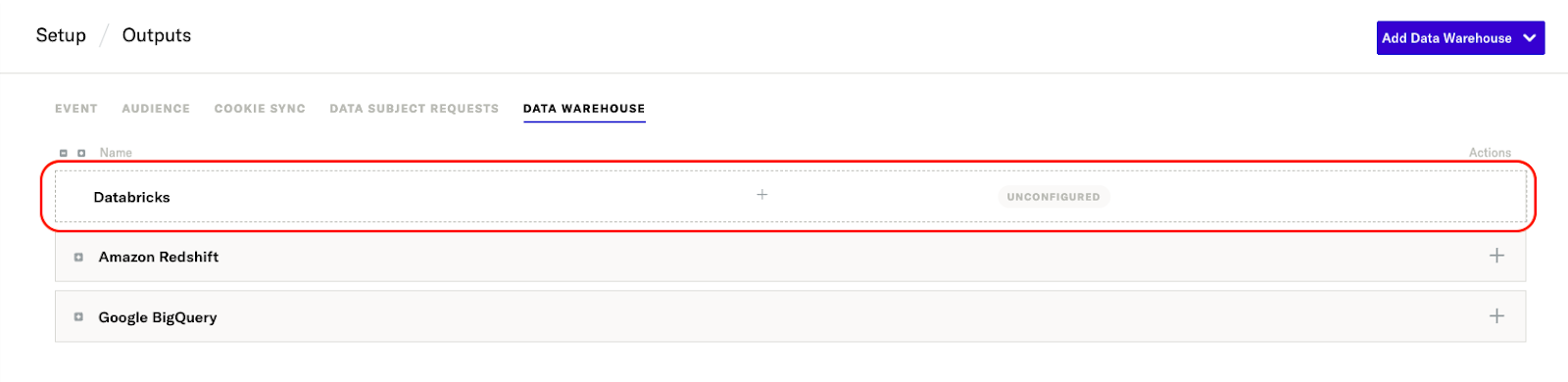
- Enter a unique Configuration name, and check Use same settings for Development & Production, if you want to use the same configuration settings for both your development and production data.
- Click Save.
- You will be taken to the Settings tab for your new configuration. Under Databricks Parameters, enter the following:
-
Server Host Name: The URL for the location where your SQL Warehouse is hosted. The URL you enter must end in either
.cloud.databricks.comorazuredatabricks.net.- If you host your SQL warehouse in Databricks, the URL in your browser after logging into your account will resemble
<deployment-name>.cloud.databricks.com. This is the value of your server host name. - If you host your SQL warehouse at
azuredatabricks.net, enter its full URL (including.azuredatabricks.net) for your server host name.
- If you host your SQL warehouse in Databricks, the URL in your browser after logging into your account will resemble
- Warehouse ID: The ID of the SQL Warehouse you created in 2 Create a SQL Warehouse.
- Catalog Name: The name of the Catalog you created in 3 Create a new Catalog.
- Schema Name: The name of the Schema you created in 4 Create a new Schema.
- Client ID: The Client ID you generated for your service principal in 1 Create a new Service Principal.
- Client Secret: The Client Secret you generated for your service principal in 1 Create a new Service Principal.
-
Event Stats Threshold: the number of events that must be reached before mParticle begins adding additional events to their own dedicated table.
- Until this threshold is reached, all events will be uploaded to a common table.
2. Create a connection with your new Databricks output
- From your mParticle account, navigate to Connections > Connect.
- Select one of your configured inputs that you want to forward data to Databricks from
- Click Connect Output, and select Databricks from your list of configured outputs.
- Set Connection Status to Active or Inactive. You can always activate a connection later after completing the configuration, but only active connections will forward data.
- If you enable Send Batches without Events, mParticle will forward all batches to Databricks, even if they only contain user data with no event data.
-
For feed connections only: If you enable Split Partner Feed Data by Event Name, mParticle will separate partner feed data by each unique event name. If you leave this setting disabled, mParticle will place all data from a single partner feed into a single table.
- This setting only applies to partner feed data. If you create a connection to Databricks using one of the other platform inputs, mParticle will place data from that input into a single table.
-
For feed connections only: Enter an optional, custom name for the table mParticle will add your data to.
- If left blank, mParticle will use the name of the partner.
- This setting is ignored if Split Partner Feed Data by Event Name is enabled.
- Click Add Connection.
Data mapping
All Databricks tables that mParticle generates are created within the schema you created in step 4 of the prerequisites. Databricks refers to databases and schemas interchangeably. The schema you create when configuring this integration serves as the main database that will contain the actual tables of data forwarded from mParticle. For more information, read about schemas in the Databricks documentation.
When mParticle adds data to a table in your Databricks schema, all the main objects and fields listed in the mParticle JSON schema are automatically mapped to objects and fields within Databricks. This includes complex objects or collections, allowing you to forward any event data from mParticle to Databricks.
For example, see the following sample CommerceEvent with a ProductAction field after it has been forwarded to Databricks:
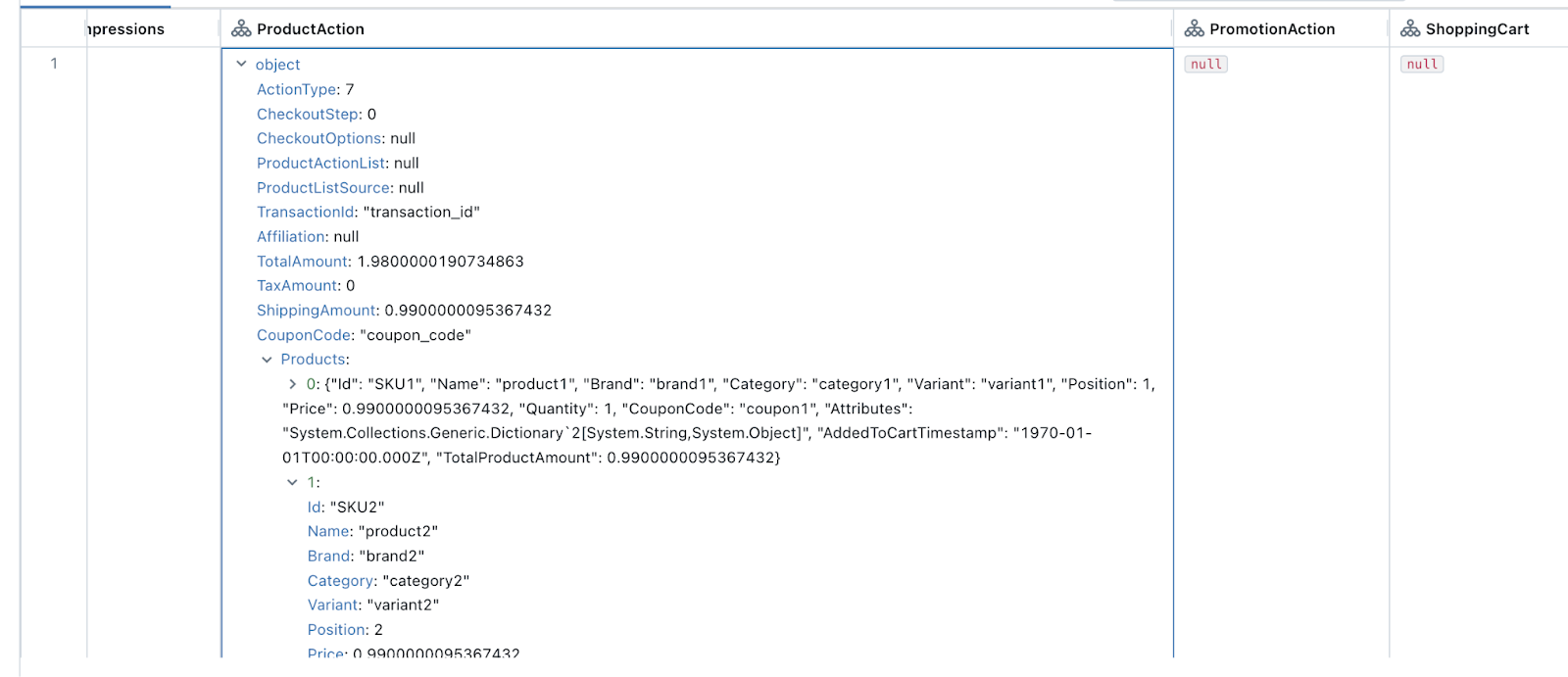
The same associated event data that was available in mParticle is queryable within Databricks.
What tables will my data be added to?
When determining which table a given event will be added to in Databricks, mParticle employs a cache that tracks all events forwarded to Databricks in the given workspace within the last 30 days.
The Event Stats Threshold configuration setting is cross-referenced with this cache to determine how many events must be forwarded to Databricks before mParticle begins adding them to their own, dedicated table.
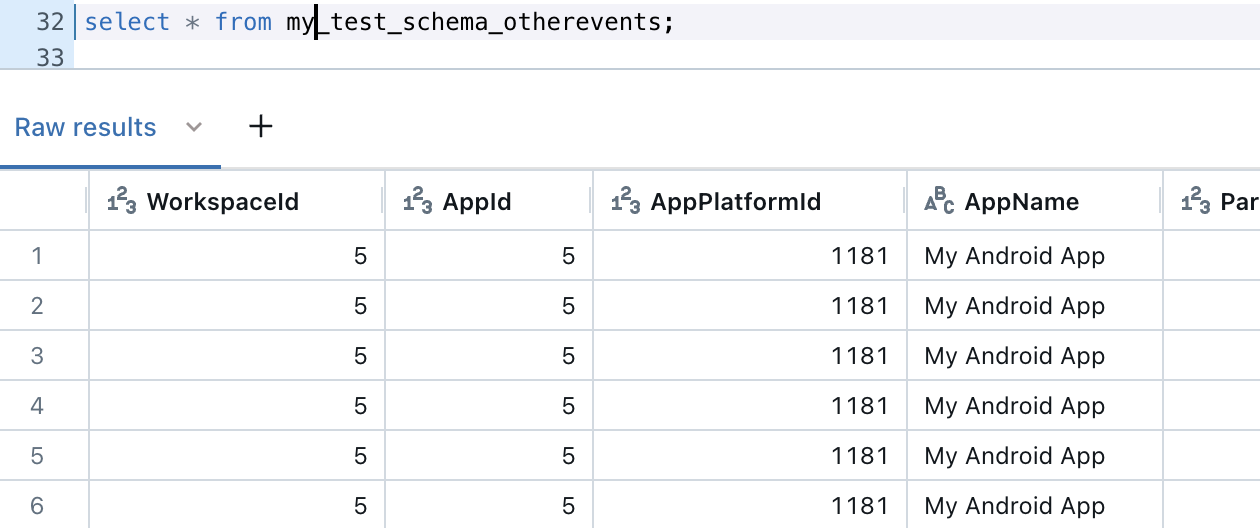
If a given event type’s frequency exceeds the configured Event Stats Threshold, then those events will start to be uploaded to their own dedicated table. Until the threshold is reached, events are uploaded to the common table with the name [your-schema-name]_otherevents table.
Partner Feed connection settings
The only exception to how mParticle adds your data to Databricks tables pertains to Feed connections. There are two special settings for Databricks Feed connections that can influence the tables events are added to.
Databricks Table Name
When creating a Databricks connection, you can specify a name for a table that mParticle will create to store your feed data in. If you leave this setting blank, mParticle creates a table with the name set to the partner feed name. This setting is only applicable to feed inputs.
If Split Partner Feed Data by Event Name is enabled, this setting is ignored.
Split Partner Feed Data by Event Name
When creating a Databricks connection, you can enable a setting called Split Partner Feed Data by Event Name. If enabled, then mParticle will create a separate table for each unique event name forwarded to Databricks. If this setting is disabled, then all Partner feed data is added to a single table.
Data forwarding
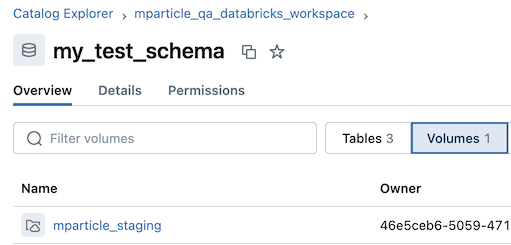
When forwarding event data to Databricks, mParticle generates an OAuth access token using the Service Principal credentials you set up in 2 Create a new Service Principal. After authenticating to Databricks with the OAuth access token, mParticle creates a new Unity Catalog Volume called mparticle_staging under the schema you set up in 4 Create a new schema. This Unity Catalog Volume acts as a staging area for your data before it’s ultimately loaded into the appropriate Databricks table.
All data ingested into mParticle that is to be forwarded to Databricks is written to parquet files, which are uploaded to the staging Unity Catalog Volume in Databricks. mParticle then automatically issues the necessary commands to load the parquet data into the respective tables, as well as clean-up any previously-loaded files.
Upload frequency
mParticle forwards data to Databricks in bulk. By default, uploads occur every 90 minutes or until 100,000 messages have accumulated in the upload queue, whichever comes first.
To adjust these thresholds, reach out to your mParticle account representative.
Accessing your data in Databricks
Once data has been loaded into a given table in your Databricks workspace, it can be easily queried using standard SQL syntax. This can be accomplished from within Databricks’ SQL Editor.
Settings reference
Configuration settings
| Setting name | Type | Required? | Encrypted? | Default setting | Description |
|---|---|---|---|---|---|
| Server Host Name | string | yes | no | null | The location of where your SQL warehouse is hosted. Must end in either .cloud.databricks.com or azuredatabricks.net. |
| Warehouse ID | string | yes | no | null | The SQL Warehouse ID upon which to execute SQL statements. |
| Service Principal Client ID | string | yes | no | null | The dedicated Service Principal’s Client ID, which will be used to generate OAuth Access Tokens to facilitate future uploads. |
| Service Principal Client Secret | string | yes | yes | null | The dedicated Service Principal’s Client Secret, which will be used to generate OAuth Access Tokens to facilitate future uploads. |
| Catalog Name | string | yes | no | null | The default catalog for statement execution. |
| Schema Name | string | yes | no | null | The default schema for statement execution. |
| Events Threshold | int | yes | no | 10000 | The threshold to determine the number of events that need to be seen before we start forwarding them to their own, dedicated table. Until this threshold is reached, events will be uploaded to a common table. |
Connection settings
| Setting name | Type | Required | Default | Input | Description |
|---|---|---|---|---|---|
| Databricks Table Name | string | no | null | Feed | Table name for this partner feed. If not set, the partner name will be used. Only applicable to feeds inputs, no effect on apps inputs. If “Split Partner Feed Data by Event Name” checkbox is enabled, this setting is not used. |
| Split Partner Feed Data by Event Name | boolean | no | false | Feed | If enabled, split partner feed data by event name. Otherwise load data into the same table. |
| Send Batches without Events | boolean | no | true | All | If enabled, an event batch that contains no events will be forwarded. |
- Last Updated: March 31, 2026